




In questa serie di articoli vi parliamo del tema dei dati nel tennis, con il proposito – un po’ ambizioso, ammettiamo – di portarvi per mano da concetti semplici a concetti più complessi. Con l’obiettivo di aiutarvi a comprendere perché il futuro del tennis, ma già in parte il presente, sarà fortemente caratterizzato dai numeri e dai dati.
Questo articolo è il quinto della serie. Trovate i primi quattro qui:
- Leggi anche – Tennis e dati: la nostra serie di articoli
Dopo aver discusso di dati, come nel secondo articolo della nostra serie in cui abbiamo elencato quelli disponibili e parlato di possibili metriche, proviamo ora a passare dalla teoria alla pratica. Il nostro presupposto è molto semplice: giocando con i dati, possiamo costruire un contesto e rendere più ricca la fruizione della cronaca di un match.
In fin dei conti, che si stia guardando un match di tennis oppure osservando un’opera d’arte, è probabile che quanto più siamo in grado di contestualizzare l’evento, tanto più siamo in grado di cogliere significati ulteriori rispetto al mero dato sensoriale. In un certo senso, il paragone con una visita guidata potrebbe reggere; l’illustrazione di un’opera d’arte può passare, ad esempio, per diversi chiavi di lettura – iconologia, sociologia, estetica – e ognuna di queste ha le sue ‘cassette degli attrezzi’ concettuali. Tanto più è ampio il bagaglio a disposizione, tanto più sarà possibile ritrovare per ogni occasione lo strumento più confacente all’analisi di una determinata chiave di lettura. Allo stesso modo, applicare le diverse categorie della filosofia e della letteratura è un modo per arricchire la narrazione sportiva, un po’ nel solco della scuola di grandi penne come Brera o Clerici.
Per fortuna, anche i comuni mortali che non rientrano in questa categoria possono offrire spunti interessanti al lettore, come a suo tempo aveva perfettamente capito Rino Tommasi. Ovviamente stiamo parlando della strada dei numeri; oggi non sono più tempi eroici in cui ci si doveva affidare alla pura memoria, come faceva proprio Rino Tommasi, ma anzi si va verso un modello scientifico di sfruttamento dati, tanto nello sport quanto negli altri ambiti economici e produttivi. L’analisi dei dati è dunque un modo per dare un contesto a ciò che si vuole raccontare al fine di agganciarlo con altre situazioni e creare una rete di connessioni e una narrazione. Lontana dall’opinione e più vicina alla realtà dei fatti.
Bene, posto che la supercazzola è stata lanciata, rimbocchiamoci le mani e vediamo concretamente come possiamo declinare tutte queste belle parole. Prendiamo ad esempio un match che parecchi di noi ricorderanno, quello fra Federer e Djokovic a Parigi Bercy nel 2018 e usiamolo come cavia (in realtà lo avevamo già fatto in questo articolo). Proviamo infatti a raccontarlo nuovamente, questa volta usando i ‘magri’ dati ufficiali messi a disposizione dall’ATP. In un lavoro successivo invece andremo a vedere cosa invece potremo fare con un livello di analisi più granulare.
Come ricordato nel secondo articolo di questa serie, cerchiamo di utilizzare il meglio i numeri relativi alla sola situazione di gioco su cui abbiamo a disposizione dati completi, ovvero il servizio, e come questo si rifletta rispetto all’andamento dei singoli punti. Abbiniamo poi a questo ‘oggetto’ alcuni semplici considerazioni, volte a contestualizzare il match che ci interessa:
- Abbiamo una profondità storica di sfide fra i due contendenti? O dobbiamo utilizzare delle proxy (un dato più generico, una sorta di ‘dato vicario’) come le performance medie per classi di ranking?
- Possiamo identificare delle tendenze?
- Possiamo identificare degli schemi che hanno portato in passato uno dei due giocatori a vincere?
Insomma, la domanda più generale è la seguente: possiamo collocare il match che ci interessa in un determinato contesto? La risposta, pur con tutti i limiti del caso, è affermativa. Torniamo quindi al match di Bercy ’18.
Queste sono le metriche di base che possiamo costruire a partire dal servizio, sulla base di famigerati dati ATP:
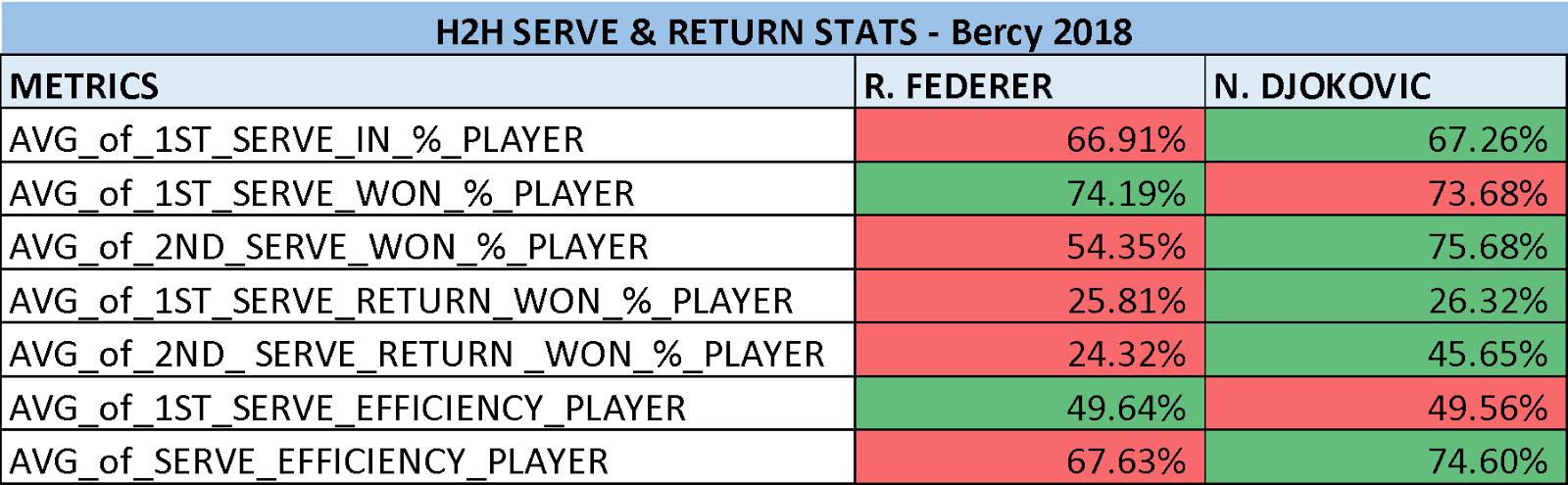
Abbiamo quindi di fronte una partita combattuta in cui il serbo l’ha spuntata per un’incollatura, 766 57 763. Tuttavia, l’impressione è che il predominio di Nole sia stato piuttosto netto a giudicare dai numeri, e che sulla base di questi dati avremmo potuto ipotizzare una vittoria del serbo in due set. Cosa succede se però allarghiamo lo spettro d’analisi e introduciamo una dimensione temporale alla nostra narrazione? Questi dati in sé per sé ci dicono poco, ma se messi in relazione a quanto accaduto nel corso delle sfide precedenti tra Federer e Djokovic possono dirci molto di più. Approfittando della profondità storica della rivalità, possiamo permetterci di applicare un filtro al campione dei match, andando a considerare solo quelli avvenuti su superfici rapide (con un semplice algoritmo relativo alle performance medie al servizio dei vari tornei dal 1991 ad oggi; se siete curiosi a riguardo, poi vi spieghiamo).
Ecco il dettaglio della stessa statistica, ‘spalmata’ però su tutti i match giocati tra i due sul veloce.

Il quadro comincia a prendere forma e possiamo accorgerci di come rispetto alla media delle osservazioni i dati – che prima erano notevolmente sbilanciati a favore del serbo – adesso risultano molto più equilibrati.
Si può vedere che in generale, se Federer ‘vive o muore’ con la sua prima di servizio, in realtà la sua performance è vicinissima a quella del serbo: ci concentriamo spesso sulle indubbie capacità in risposta di Nole, ma a volte dimentichiamo quanto sia efficiente quando va in pressione dopo aver servito la prima.
Tornando al match di Bercy, emerge anche visivamente quale sia la chiave di lettura più corretta. Federer ha servito meglio rispetto alla media degli scontri con Djokovic, ma in risposta… non ci ha capito molto; per dirla in altri termini, Roger ha lottato in trincea al servizio, mentre in risposta volente o nolente ha dovuto passare la mano, con un Nole che è invece è andato in cruise control praticamente per tutto il match.

Tuttavia, era prevedibile che le statistiche basate sulla media storica dei match portassero a un riequilibrio, visto che la media è composta da match vinti e match persi. Proprio questo concetto è un punto fondamentale della nostra analisi: un match vinto e un match perso sono due oggetti spesso molto diversi con caratteristiche peculiari. Inoltre, concentrarsi sui match vinti ha il grosso pregio di dare una parvenza di fondamento ai classici commenti ‘sentimentali’ che (troppo) spesso ascoltiamo durante una cronaca: avete presente il telecronista preveggente che dice “Roger deve servire almeno il 70% di prime, altrimenti è spacciato”? Perché proprio 70% e non 68%, o 71%? 2 o 3 punti percentuali non sono roba da poco nel tennis!
Per questo motivo, se proprio dobbiamo dare i numeri cerchiamo di farlo con un minimo di cognizione di causa. Analizziamo allora la performance di Federer secondo le diverse metriche prese in esame per capire quanto ci è andato vicino o lontano:
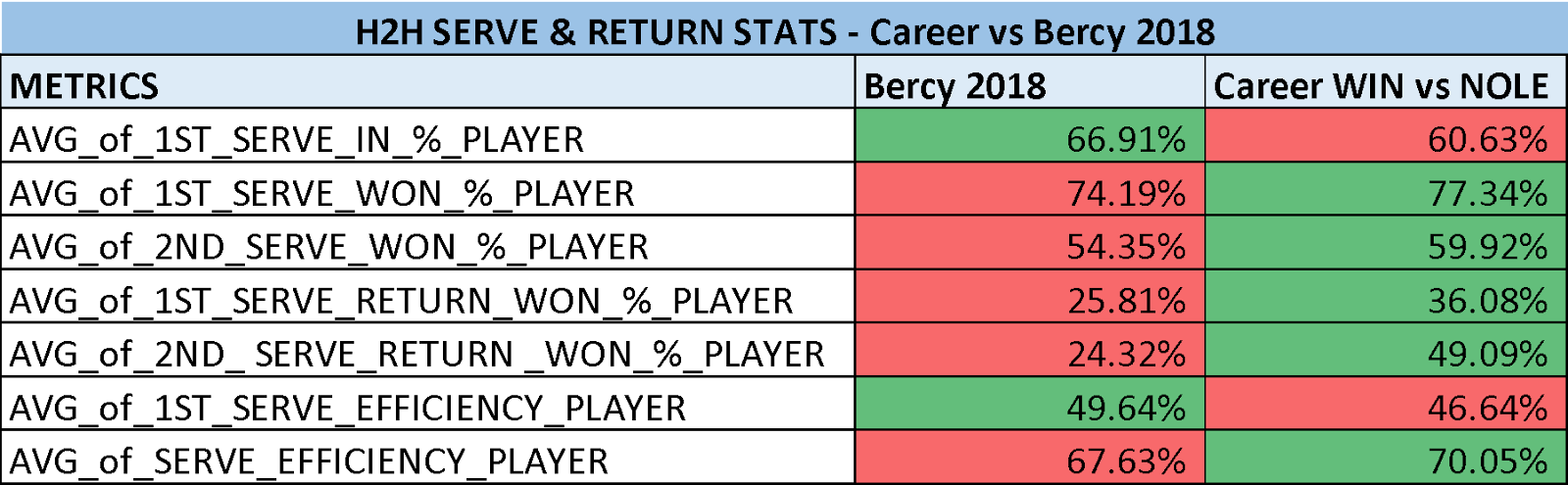
Così ad occhio, sembra essere rimasto abbastanza lontano dai numeri che avevano caratterizzato le sue vittorie precedenti contro Djokovic. Si potrebbe quasi dire, statisticamente parlando, che l’eventuale vittoria dello svizzero sarebbe stata un magnifico furto con scasso (e chissà che psicologicamente non avrebbe potuto avere qualche effetto a Church Road nel luglio 2019…).
Ricordiamo però che si tratta di semplice medie, dunque cerchiamo di dare una rappresentazione grafica del match rispetto ai ‘macro-aggregati’ di servizio e palleggio. Nel dare una rappresentazione cartesiana abbiamo cercato di trovare insiemi omogenei che variando potessero muoversi in sincrono, generando così un grafico leggibile ed esplicativo; abbiamo rappresentato in ascissa (asse orizzontale) la percentuale di prime di servizio in campo e in ordinata (asse verticale) la percentuale di punti vinti con la prima prima. Il rapporto tra le due metriche è dovuto al principio secondo cui per aumentare la percentuale di successo sulla prima è fisiologico dover rischiare qualcosa in più, abbassando così la percentuale di prime; ne consegue che l’esito ‘numerico’ è neutrale.
Pertanto abbiamo tracciato una linea nera che passa per la media e divide l’area del grafico in due quadranti: i punti (match) sopra la linea sono quelli per cui l’efficienza al servizio sulla prima è stato superiore alla media, e viceversa per quelli sotto la linea nera. Abbiamo poi colorato di azzurro i match vinti da Roger e di rosso quelli vinti da Nole, tracciando anche la retta di regressione che indica la tendenza di vittoria per il serbo e per lo svizzero.
Ripassino statistico: una retta di regressione è una retta che minimizza la distanza fra i ‘puntini’ appartenenti a una stessa classe di dati (in questo caso le vittorie di Djokovic o Federer) ipotizzando così un modello ragionevole da applicare a dati futuri. Si tratta di un metodo statistico per stimare il valore atteso di una variabile dipendente al variare della variabile indipendente. Possiamo dunque attenderci che tutti i ‘pallini’ corrispondenti alle vittorie di Djokovic o Federer siano nei pressi della rispettiva retta di regressione, nonché prevedere in quale ‘range’ di percentuale di prime in campo sia situato un match in cui Federer ha vinto una determinata percentuale di punti con la prima.

Come possiamo vedere con immediatezza, la performance di Roger a Bercy è stata più che adeguata e l’unica volta che è riuscito a battere Nole di fatto senza un sostanzioso aiuto del servizio è stato nel 2010 in Canada (l’eccezione indicata dalla freccia). Viceversa, Nole è ormai diventato un habitué nel fare scorribande e portare a casa partite in cui il servizio di Roger ha comunque fatto egregiamente il suo dovere: basti vedere quanti punti stanno non solo sopra la linea nera, ma anche quella blu che definisce la linea di tendenza per i match vinti dallo svizzero.
In chiusura, consideriamo un esempio della capacità di Roger di vincere punti non determinati in maniera significativa dal servizio, ovvero i punti giocati sulla propria seconda e in risposta alla seconda del serbo.

I risultati parlano chiaro. Siamo nella parte bassa del grafico, ben lontani dalla media delle performance messe in mostra dallo svizzero. I precedenti in cui Roger era riuscito a cavarsela senza avere la meglio nelle situazioni di palleggio (possiamo approssimare che la maggior parte dei punti giocati sulla seconda si traducono in un palleggio più lungo) ormai risalgono a oltre dieci anni fa, e la dura realtà ormai è chiara: o Federer riesce a stare ‘nella stratosfera’ del grafico viaggiando oltre il 60 percento sulla propria seconda o il suo destino è segnato. Solo mettendo la museruola alla risposta del serbo, Roger è poi in grado di sciorinare le sue frustate liquide capaci di demolire le difese di Djokovic.
Insomma, il concetto è chiaro: ripercorrendo lo storico dei dati, siamo poi in grado di tracciare delle mappe che possano (con un briciolo di argomentazione) collocare i match di cui vogliamo parlare in un contesto logico-razionale. Ci piacerebbe adesso sapere cosa ne pensate, e se raccontare le partite anche in quest’ottica vi sembra una buona idea. Commentate numerosi, vi aspettiamo per il prossimo articolo che sarà l’ultimo di questa serie – ma non certo l’ultimo in generale: il viaggio nel mondo dei dati è appena iniziato!





