




Off-season, terreno di novità e di esperimenti. Per questo mese (e più, visto lo slittamento dell’Australian Open) senza tennis abbiamo deciso di aprire un nuovo fronte e di affrontarlo con la calma che solo l’assenza del tran tran dei tornei può concederci. In questa serie di articoli vi parleremo del tema dei dati nel tennis, con il proposito – un po’ ambizioso, ammettiamo – di portarvi per mano da concetti semplici a concetti più complessi. Con l’obiettivo di aiutarvi a comprendere perché il futuro del tennis, ma già in parte il presente, sarà fortemente caratterizzato dai numeri e dai dati.
Le prime statistiche ufficiali relativi a singoli match sono state registrate a partire dal 1991. Per farvi un’idea, se andate nel sito ATP e cercate di recuperare gli head to head fra Edberg e Becker, vedrete il dettaglio dei match solo a partire dall’inizio degli anni 90. Per cui una prima cosa la possiamo dire senz’altro: prima di quella data, giocatori, coach e giornalisti potevano fare soltanto una cosa: tirare a indovinare… o chiamare Rino Tommasi.
A partire dagli anni 90 sono cominciate le raccolte sistematiche di dati sul tennis, ma purtroppo non siamo andati molto oltre, a parte qualche grafica che viene generosamente elargita nei tornei dello Slam e nei Master 1000. Sul tema dei dati, della proprietà, di chi li raccoglie, rimandiamo tuttavia a episodi futuri della nostra serie di articoli; oggi ci concentriamo su come descrivere questi fantomatici dati.
Il tennis è uno sport che ben si presta all’analisi dei dati, caratterizzato da unità elementari (i singoli punti) gerarchicamente inquadrato in strutture discrete (game e set) dall’esito binario. Peccato, però, che i dati disponibili al pubblico siano poco più che briciole: aggregati di singole strutture gerarchiche (punti, game e set vinti), singoli punti importanti vinti (break point) e performance aggregate sull’unico colpo decentemente tracciato (il servizio). Di nuovo, se tornate sul sito ATP vedrete che i dati disponibili si riducono a serve stats e poco altro.
Quindi, quali sono i dati con cui vorrebbero ‘giocare’ tennisti, coach, giornalisti e semplici appassionati? Proviamo allora a riepilogare le diverse tipologie.
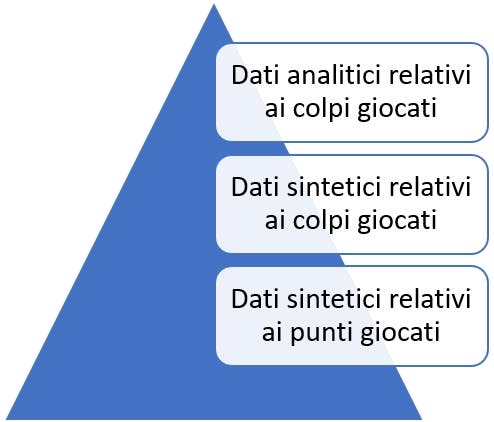
LA PRIMA CATEGORIA: I DATI PIÙ GREZZI
I dati sintetici relativi ai punti giocati sono dati complessivi, che ci raccontano ad esempio quanti punti sono stati vinti da un giocatore o quanti sono stati i break point giocati. La prospettiva di analisi sono i punti, l’unità gerarchica elementare. Il punto è quindi l’unita di base delle statistiche disponibili, a cui è associata una sola informazione relativa ai colpi giocati, ovvero il servizio. In pratica, il punto, pur essendo l’unità elementare del punteggio, è una ‘scatola nera’ che può avere la composizione più varia e di cui l’unico attributo noto è “punto giocato sulla prima di servizio” o “punto giocato sulla seconda di servizio”. Fine della favola. Lasciate ogni speranza voi che cercate di dare rappresentazioni statistiche di un match e di serie di dati, almeno con riferimento ai dati ufficiali liberamente disponibili e pubblicati dall’ATP.
Che il servizio sia il singolo colpo più importante nel tennis (probabilmente assieme alla risposta al servizio) è cosa ormai consolidata, basti pensare che in media il 60-70% dei punti giocati ricade nella categoria ‘sotto i cinque colpi giocati’. Certo è che fare affidamento solo su queste informazioni è parecchio limitante per chi cerca di spiegare con i numeri cosa accade in una partita e per chi prova a tracciare linee di tendenza generali. I risultati più interessanti che possiamo ricavare sono relativi alla correlazione fra match vinti e persi con riferimento al servizio e ai punti importanti giocati.
Non a caso, nella sezione statistica del sito ATP – l’ATP leaderboard – potete trovare solo dati relativi a performance al servizio, in risposta e sui punti importanti. Della robustezza di questi indicatori abbiamo già parlato, ma sull’argomento ha scritto anche Stephanie Kovalchick, una delle accademiche più influenti in materia di data analytics che collabora anche con Tennis Australia. Partendo da questi dati, tuttavia, si possono costruire anche analisi storiche; di seguito l’esempio di una statistica che mette a confronto lo scarto percentuale – positivo o negativo – fra la percentuale di punti vinti al servizio e la percentuale di palle break salvate da Federer in partite lottate, vinte e perse.

LA SECONDA CATEGORIA: I DATI DI SINTESI
La seconda categoria di dati è quella relativa a dati di sintesi su singoli colpi giocati. Non preoccupatevi se sembra complesso, ora vi spieghiamo.
Detto del servizio, per il quale almeno abbiamo l’informazione binaria se sia stata giocata una prima o una seconda di servizio, ci rimane tutto il resto del mondo da esplorare. Fortunatamente, i tornei dello Slam e i Master 1000 (in misura minore i 500, per i quali la ricchezza del dato è inferiore) stanno raccogliendo in forma strutturata (ma di difficile accessibilità) questi dati. È evidente quindi che si apre un mondo: dati quali lunghezza degli scambi, vincenti, errori forzati, velocità e rotazione di palla, altezza della palla sopra la rete e la fondamentale distinzione tra dritti, rovesci e colpi di volo diventano disponibili.
Per approssimazione, quella che abbiamo già definito una scatola nera, ovvero la composizione ‘reale’ dei singoli punti, si apre un po’ e racconta qualche segreto in più. Non sappiamo più soltanto se il punto si è giocato su una prima o su una seconda e chi l’ha vinto, ma anche quanto è stato lungo e come si è concluso (rovescio vincente, gratuito di dritto, volée vincente). Rimane però un problema. Questi dati sono aggregati, quindi gli schemi di gioco di una partita possono essere esplorati soltanto per deduzione. Tuttavia, è già un grosso passo in avanti se paragoniamo tutto questo con i dati normalmente disponibili.
A titolo di esempio riportiamo un’estrazione basta su dati Hawkeye sintetici, raccolti fra 2017 e 2019 su Shapovalov.

Questa piccola estrazione mette in evidenza il delta (differenza) fra match vinti e match persi da Shapovalov: mentre tanti appassionati rimangono abbagliati dello splendido rovescio del canadese, i numeri raccontano che per ipotizzare se una partita verrà vinta o persa da Denis bisogna invece guardare il suo dritto; nei match vinti, i diritti vincenti sono 2,7 volte quelli del suo avversario, mentre in quelli persi solo 1,8. Analogamente, gli errori non forzati di dritto sono sono 1,6 volte quelli dell’avversario nei match vinti mentre schizzano a 2,8 in quelli persi. Se riusciremo a raccogliere un campione di dati sufficienti, proveremo a vedere come sono andate le cose per Denis nel 2020, per verificare i miglioramenti registrati quest’anno dal canadese. Appuntamento a qualche articolo futuro, se il tema continuerà a interessarvi.
LA TERZA CATEGORIA: I DATI HAWKEYE
Infine la terza categoria riguarda i dati analitici dei singoli colpi giocati, ovvero il dato grezzo Hawkeye, il cui accesso è però concesso solo a pochi eletti; si vocifera che Golden set analytics, uno dei colossi dei big data nel tennis, ne sia in possesso e riesca pertanto, dietro lauto compenso, a fornire insight avanzati ai tennisti che ne hanno bisogno; tra questi c’è anche Federer, come vi abbiamo già raccontato. Tuttavia, vista la generale indisponibilità di tali dati e l’ interesse crescente di giocatori e coach, stanno nascendo diverse start-up e liberi professionisti che offrono questo tipo di servizi.
Gli approcci sono attualmente basati sul charting dei match svolto manualmente, allo scopo di arricchire i dati ATP e costruire una base dati sufficiente per poter effettuare rilevazioni sui singoli giocatori e sulle loro caratteristiche. Stanno tuttavia emergendo approcci basati sull’utilizzo di tecniche di intelligenza artificiale che consentono di automatizzare questo processo di raccolta dati. e che in futuro potrebbero colmare quel gap di dati attualmente non forniti dalle fonti ufficiali. In questi casi, una gestione dei dati unita a modalità di presentazione che forniscano insight di facile utilizzo e interpretazione può portare a un concreto upgrade nell’attività dei coach di preparazione dei match.
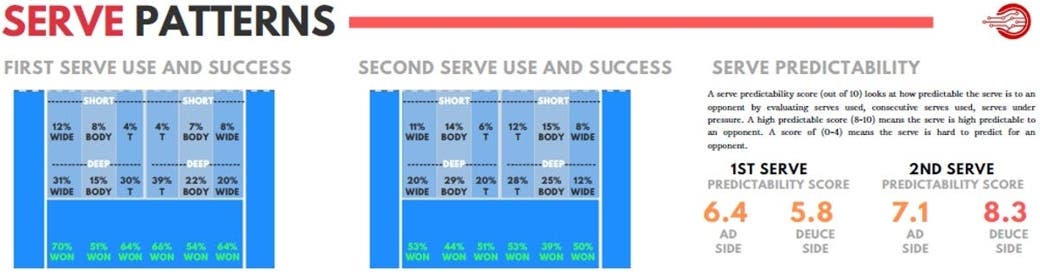
Riportiamo di seguito un esempio di insight di Data Driven Sports Analytics.
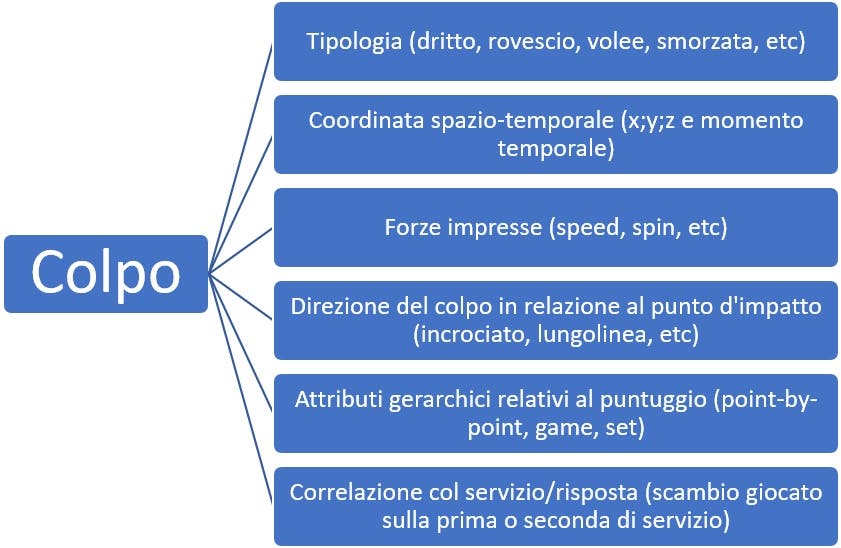
Per concludere, ogni colpo giocato su un campo da tennis può essere considerato come l’unità elementare, il mattoncino lego su cui è costruito un match di tennis; questi mattoncini sono poi aggregati in strutture discrete che seguono le regole definite nella gerarchia di punteggio, e se fossero gli oggetti di un database sarebbero caratterizzati dai seguenti attributi.
Ad oggi abbiamo a disposizione, da fonti pubbliche liberamente accessibili, solo dati aggregati relativi al servizio, e su una base molto più limitata dati di sintesi più ricchi ripresi da dati Hawkeye per tornei Master 1000 e Grand Slam. Il futuro non potrà che essere più roseo, da questo punto di vista. E se al termine di questo articolo vi state chiedendo come vengono raccolti materialmente questi dati sul campo, beh, l’appuntamento è tra sette giorni. Ve lo racconteremo.





